La fonction de distribution dans ce cas, selon (5.7), prendra la forme :
où : m est l'espérance mathématique, s est l'écart type.
La distribution normale est aussi appelée gaussienne du nom du mathématicien allemand Gauss. Le fait qu'une variable aléatoire ait une distribution normale de paramètres : m,, est noté comme suit : N (m, s), où : m =a =M ;
Très souvent, dans les formules, l'espérance mathématique est notée un . Si une variable aléatoire est distribuée selon la loi N(0,1), alors on l'appelle une valeur normale normalisée ou standardisée. Sa fonction de distribution est de la forme :
|
|
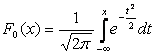 .
.Le graphique de la densité de la distribution normale, appelée courbe normale ou courbe gaussienne, est illustré à la Fig. 5.4.

Riz. 5.4. Densité de distribution normale
La détermination des caractéristiques numériques d'une variable aléatoire par sa densité est considérée sur un exemple.
Exemple 6.
Une variable aléatoire continue est donnée par la densité de distribution : ![]() .
.
Déterminez le type de distribution, trouvez l'espérance mathématique M(X) et la variance D(X).
En comparant la densité de distribution donnée avec (5.16), nous pouvons conclure que la loi de distribution normale avec m =4 est donnée. Donc, espérance mathématique M(X)=4, variance D(X)=9.
Écart type s=3.
La fonction de Laplace, qui a la forme :
|
|
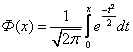 ,
,est liée à la fonction de distribution normale (5.17), par la relation :
F 0 (x) \u003d F (x) + 0,5.
La fonction de Laplace est impaire.
Ô(-x)=-Ô(x).
Les valeurs de la fonction de Laplace Ф(х) sont tabulées et extraites du tableau en fonction de la valeur de x (voir annexe 1).
La distribution normale d'une variable aléatoire continue joue un rôle important dans la théorie des probabilités et dans la description de la réalité ; elle est très répandue dans les phénomènes naturels aléatoires. En pratique, il existe très souvent des variables aléatoires qui sont formées précisément à la suite de la sommation de nombreux termes aléatoires. En particulier, l'analyse des erreurs de mesure montre qu'elles sont la somme de plusieurs types d'erreurs. La pratique montre que la distribution de probabilité des erreurs de mesure est proche de la loi normale.
En utilisant la fonction de Laplace, on peut résoudre des problèmes de calcul de la probabilité de tomber dans un intervalle donné et un écart donné d'une variable aléatoire normale.
Contrairement à une variable aléatoire discrète, les variables aléatoires continues ne peuvent pas être spécifiées sous la forme d'un tableau de sa loi de distribution, car il est impossible de répertorier et d'écrire toutes ses valeurs dans une certaine séquence. Une façon possible de définir une variable aléatoire continue est d'utiliser une fonction de distribution.
DÉFINITION. La fonction de distribution est une fonction qui détermine la probabilité qu'une variable aléatoire prenne une valeur représentée sur l'axe réel par un point à gauche du point x, c'est-à-dire
Parfois, au lieu du terme "Fonction de distribution", le terme "Fonction intégrale" est utilisé.
Propriétés de la fonction de distribution :
1. La valeur de la fonction de distribution appartient au segment : 0F(x)1
2. F(x) est une fonction non décroissante, c'est-à-dire F(x 2)F(x 1) si x 2 >x 1
Corollaire 1. La probabilité qu'une variable aléatoire prenne une valeur contenue dans l'intervalle (a,b) est égale à l'incrément de la fonction de répartition sur cet intervalle :
P(aX
Exemple 9. Une variable aléatoire X est donnée par une fonction de distribution :

Trouver la probabilité qu'à la suite du test, X prenne une valeur appartenant à l'intervalle (0 ; 2) : P(0 Solution : Puisque sur l'intervalle (0;2) par condition, F(x)=x/4+1/4, alors F(2)-F(0)=(2/4+1/4)-(0 /4+1/4)=1/2. Donc P(0 Corollaire 2. La probabilité qu'une variable aléatoire continue X prenne une valeur définie est égale à zéro. Corollaire 3. Si les valeurs possibles d'une variable aléatoire appartiennent à l'intervalle (a;b), alors : 1) F(x)=0 pour xa ; 2) F(x)=1 pour xb. Le graphique de la fonction de distribution est situé dans la bande délimitée par des droites y=0, y=1 (la première propriété). Lorsque x augmente dans l'intervalle (a;b), qui contient toutes les valeurs possibles de la variable aléatoire, le graphique "monte". Pour xa, les ordonnées du graphique sont égales à zéro ; en xb, les ordonnées du graphe sont égales à un : Exemple 10. Une variable aléatoire discrète X est donnée par un tableau de distribution : Trouvez la fonction de distribution et construisez son graphique. DÉFINITION: La densité de distribution de probabilité d'une variable aléatoire continue X est la fonction f (x) - la dérivée première de la fonction de distribution F (x): f (x) \u003d F "(x) Il découle de cette définition que la fonction de distribution est la primitive de la densité de distribution. Théorème. La probabilité qu'une variable aléatoire continue X prenne une valeur appartenant à l'intervalle (a ; b) est égale à une certaine intégrale de la densité de distribution, prise dans l'intervalle de a à b : Propriétés de densité de probabilité : 1. La densité de probabilité est une fonction non négative : f(x)0. Exemple 11. Étant donné la densité de distribution de probabilité d'une variable aléatoire X Solution : Probabilité souhaitée : Étendons la définition des caractéristiques numériques des quantités discrètes aux quantités continues. Soit une variable aléatoire continue X donnée par la densité de distribution f(x). DÉFINITION. L'espérance mathématique d'une variable aléatoire continue X, dont les valeurs possibles appartiennent au segment , est appelée intégrale définie : M(x)=xf(x)dx (9) Si les valeurs possibles appartiennent à l'ensemble de l'axe des abscisses, alors : M(x)=xf(x)dx (10) Le mode M 0 (X) d'une variable aléatoire continue X est sa valeur possible, qui correspond au maximum local de la densité de distribution. La médiane M e (X) d'une variable aléatoire continue X est sa valeur possible, qui est déterminée par l'égalité : P(X e (X))=P(X>M e (X)) DÉFINITION. La dispersion d'une variable aléatoire continue est l'espérance mathématique du carré de son écart. Si les valeurs possibles de X appartiennent au segment , alors : D(x)=2 f(x)dx (11) Si les valeurs possibles appartiennent à l'ensemble de l'axe des x, alors.
Répartition homogène.
valeur continue X est uniformément réparti sur l'intervalle ( un, b) si toutes ses valeurs possibles sont dans cet intervalle et que la densité de distribution de probabilité est constante : Pour une variable aléatoire X, uniformément répartie dans l'intervalle ( un, b) (Fig. 4), la probabilité de tomber dans n'importe quel intervalle ( X 1
, X 2 ) situé à l'intérieur de l'intervalle ( un, b), est égal à: Les erreurs d'arrondi sont des exemples de quantités uniformément distribuées. Ainsi, si toutes les valeurs tabulaires d'une certaine fonction sont arrondies au même chiffre, puis en choisissant une valeur tabulaire au hasard, nous considérons que l'erreur d'arrondi du nombre sélectionné est une variable aléatoire uniformément répartie dans l'intervalle distribution exponentielle.
Variable aléatoire continue X Il a distribution exponentielle Le graphique de la densité de distribution de probabilité (31) est illustré à la fig. 5. Temps J le fonctionnement sans défaillance d'un système informatique est une variable aléatoire qui a une distribution exponentielle avec le paramètre λ
, dont la signification physique est le nombre moyen de pannes par unité de temps, sans compter les temps d'arrêt du système pour réparation. Distribution normale (gaussienne).
Valeur aléatoire X Il a Ordinaire (Distribution gaussienne, si la distribution de densité de ses probabilités est déterminée par la dépendance : où m = M(X) , . À
la distribution normale est appelée la norme. Le graphique de la densité de la distribution normale (32) est représenté sur la fig. 6. La distribution normale est la distribution la plus courante dans divers phénomènes aléatoires de la nature. Ainsi, des erreurs dans l'exécution de commandes par un dispositif automatisé, des erreurs dans le lancement d'un engin spatial vers un point donné de l'espace, des erreurs dans les paramètres des systèmes informatiques, etc. dans la plupart des cas, ont une distribution normale ou proche de la normale. De plus, les variables aléatoires formées par la sommation d'un grand nombre de termes aléatoires sont distribuées presque selon la loi normale. Distribution gamma.
Valeur aléatoire X Il a distribution gamma, si la distribution de densité de ses probabilités est exprimée par la formule : où Propriétés de la fonction de distribution: 1) La fonction de répartition vérifie l'inégalité : 0≤F(x)≤1 ; 2) La fonction de distribution est une fonction non décroissante, c'est-à-dire x 2 > x 1 implique F(x2)≥F(x1). 3) La fonction de distribution tend vers 0 avec une diminution illimitée de l'argument e et tend vers 1 avec son augmentation illimitée. Tracé de la fonction de distribution Densité de probabilité(densité de probabilité) f(x) d'une variable aléatoire continue X est la dérivée de la fonction de répartition F(x) de cette variable : f(x)=F'(x) Propriétés de densité de probabilité :
1)
La densité de probabilité est une fonction positive : f(x)≥0 ; 2)
La probabilité que, à la suite du test, une variable aléatoire continue prenne des valeurs quelconques de l'intervalle (a, b) est égale à : Sous les principales caractéristiques numériques d'une variable aléatoire continue, comprenez l'espérance mathématique, la variance et l'écart type. Espérance mathématique d'une variable aléatoire continue : Dispersion d'une variable aléatoire continue ré(X)
=
M[
X
–
M(X)]
2
. (ajouter) Écart type : σ(х)= √D(X) De tous les types de distribution de variables aléatoires continues, le plus couramment utilisé distribution normale
, qui est fixé Loi de Gauss.
Ainsi, si nous avons une somme d'un grand nombre de quantités indépendantes, soumises à des lois de distribution quelconques, alors, sous certaines conditions générales, elle obéira approximativement à la loi normale. Variable aléatoire continue est dit distribué selon la loi normale, si sa densité de probabilité est : Remplacer l'expression prendra une valeur à partir de l'intervalle donné : P(un<
X<
b)
=____________________ Règle des trois sigma
:
les écarts des valeurs de la distribution normale d'une variable aléatoire par rapport à son espérance mathématique en valeur absolue ne dépassent pratiquement pas son écart type triplé. (VNS)
continu est une variable aléatoire dont les valeurs possibles occupent en permanence un certain intervalle. Si une variable discrète peut être donnée par une liste de toutes ses valeurs possibles et leurs probabilités, alors une variable aléatoire continue dont les valeurs possibles occupent complètement un certain intervalle ( un, b), il est impossible de spécifier une liste de toutes les valeurs possibles. Laisser être X est un nombre réel. La probabilité de l'événement que la variable aléatoire X prend une valeur inférieure à X, c'est à dire. probabilité d'événement X <X, noté par F(X). Si un X changements, puis, bien sûr, changements et F(X), c'est à dire. F(X) est une fonction de X. fonction de répartition appeler la fonction F(X), qui détermine la probabilité que la variable aléatoire Xà la suite du test prendra une valeur inférieure à X, c'est à dire. F(X) = R(X < X). Géométriquement, cette égalité peut être interprétée comme suit : F(X) est la probabilité que la variable aléatoire prenne la valeur représentée sur l'axe réel par un point à gauche du point X. Propriétés de la fonction de distribution. Dix . Les valeurs de la fonction de distribution appartiennent à l'intervalle : 0 ≤ F(X) ≤ 1. 2 0 . F(X) est une fonction non décroissante, c'est-à-dire F(X 2) ≥ F(X 1) si X 2 > X 1 . Conséquence 1. La probabilité qu'une variable aléatoire prenne une valeur contenue dans l'intervalle ( un, b), est égal à l'incrément de la fonction de distribution sur cet intervalle : R(un < X <b) = F(b) − F(un). Exemple. Valeur aléatoire X donnée par la fonction de distribution F(X) = Valeur aléatoire X 0, 2). D'après le corollaire 1, on a : R(0 < X <2) = F(2) − F(0). Puisque sur l'intervalle (0, 2), par condition, F(X) = + , alors F(2) − F(0) = (+ ) − (+ ) = . Ainsi, R(0 < X <2) = . Conséquence 2. La probabilité qu'une variable aléatoire continue X prendra une valeur définie, égale à zéro. trente . Si les valeurs possibles de la variable aléatoire appartiennent à l'intervalle ( un, b), alors 1). F(X) = 0 pour X ≤ un; 2). F(X) = 1 pour X ≥ b. Conséquence. Si possible valeurs VNS situé sur tout l'axe numérique OH(−∞, +∞), alors les relations limites suivantes sont vérifiées : Les propriétés considérées permettent de présenter une vue générale du graphe de la fonction de distribution d'une variable aléatoire continue : fonction de répartition VNS X appelle souvent fonction intégrale. Une variable aléatoire discrète a également une fonction de distribution : Le graphique de la fonction de distribution d'une variable aléatoire discrète a une forme en escalier. Exemple. VDS X donnée par la loi de distribution X 1 4 8 R 0,3 0,1 0,6. Trouvez sa fonction de distribution et construisez un graphique. Si un X≤ 1, alors F(X) = 0. Si 1< X≤ 4, alors F(X) = R 1 =0,3. Si 4< X≤ 8, alors F(X) = R 1 + R 2 = 0,3 + 0,1 = 0,4. Si un X> 8, puis F(X) = 1 (ou F(X) = 0,3 + 0,1 + 0,6 = 1). Ainsi, la fonction de distribution de la donnée VDS X: Graphique de la fonction de distribution souhaitée : VNS peut être spécifié par la densité de distribution de probabilité. Densité de distribution de probabilité NSV X appeler la fonction F(X) est la dérivée première de la fonction de distribution F(X): F(X) = . La fonction de distribution est la primitive de la densité de distribution. La densité de distribution est aussi appelée densité de probabilité, fonction différentielle. Le tracé de la densité de distribution est appelé courbe de distribution. Théorème 1. La probabilité que VNS X prendra une valeur appartenant à l'intervalle ( un, b), est égal à une certaine intégrale de la densité de distribution, prise dans la plage de un avant que b: R(un < X < b) = . ○ R(un < X <b) = F(b) −F(un) == . ● Signification géométrique : la probabilité que VNS prendra une valeur appartenant à l'intervalle ( un, b), est égal à l'aire du trapèze curviligne délimité par l'axe OH, courbe de distribution F(X) et directe X =un et X=b. Exemple.Étant donné une densité de probabilité VNS X F(X) = Trouver la probabilité qu'à la suite du test X prendra une valeur appartenant à l'intervalle (0.5; 1). R(0,5 < X < 1) = 2= = 1 – 0,25 = 0,75. Propriétés de densité de distribution: Dix . La densité de distribution est une fonction non négative : F(X) ≥ 0. 20 . L'intégrale impropre de la densité de distribution dans la plage de −∞ à +∞ est égale à un : En particulier, si toutes les valeurs possibles de la variable aléatoire appartiennent à l'intervalle ( un, b), alors Laisser être F(X) est la densité de distribution, F(X) est la fonction de distribution, alors F(X) = . ○ F(X) = R(X < X) = R(−∞ < X < X) = = , c'est-à-dire F(X) = . ● Exemple (*). Trouvez la fonction de distribution pour une densité de distribution donnée : F(X) = Tracez la fonction trouvée. Il est connu que F(X) = . Si un, X ≤ un, alors F(X) = = == 0; Si un un < X ≤ b, alors F(X) = =+ = = . Si un X > b, alors F(X) = =+ + = = 1. F(X) = Le graphique de la fonction recherchée : Caractéristiques numériques de NSV Espérance mathématique NSV X, dont les valeurs possibles appartiennent à l'intervalle [ un, b], est appelée l'intégrale définie M(X) = . Si toutes les valeurs possibles appartiennent à l'axe entier OH, alors M(X) = . On suppose que l'intégrale impropre converge absolument. Dispersion VNS X s'appelle l'espérance mathématique du carré de sa déviation. Si possible valeurs X appartiennent au segment [ un, b], alors ré(X) = ; Si possible valeurs X appartiennent à tout l'axe réel (−∞; +∞), alors ré(X) = . Il est facile d'obtenir des formules plus pratiques pour calculer la variance: ré(X) = − [M(X)] 2 , ré(X) = − [M(X)] 2 . Écart type NSV Х est défini par l'égalité (X) = . Commenter. Propriétés de l'espérance mathématique et de la variance DSV enregistré pour VNS X. Exemple. Trouver M(X) et ré(X) Variable aléatoire X, donnée par la fonction de distribution F(X) = Trouver la densité de distribution F(X) = = Allons trouver M(X): M(X) = = = = . Allons trouver ré(X): ré(X) = − [M(X)] 2 = − = − = . Exemple (**). Trouver M(X), ré(X) et ( X) Variable aléatoire X, si F(X) = Allons trouver M(X): M(X) = = =∙= . Allons trouver ré(X): ré(X) =− [M(X)] 2 =− = ∙−=. Allons trouver ( X): (X) = = = . Moments théoriques de NSV. Moment théorique initial d'ordre k NSV X est défini par l'égalité ν k = . Moment central théorique d'ordre k NSW Х est défini par l'égalité µk = . En particulier, si toutes les valeurs possibles X appartiennent à l'intervalle ( un, b), alors ν k = , µk = . Évidemment: k = 1: ν
1 = M(X), μ
1 = 0; k = 2: μ
2 = ré(X). Connection entre ν k et µk aimer DSV: μ
2 = ν
2 − ν
1 2 ; μ
3 = ν
3 − 3ν
2 ν
1 + 2ν
1 3 ; μ
4 = ν
4 − 4ν
3 ν
1 + 6 ν
2 ν
1 2 − 3ν
1 4 . Lois de distribution de NSV Densités de distribution VNS aussi appelé lois de distribution. La loi de la distribution uniforme. La distribution de probabilité est appelée uniforme, si sur l'intervalle auquel appartiennent toutes les valeurs possibles de la variable aléatoire, la densité de distribution reste constante. Densité de probabilité de distribution uniforme : F(X) = Son emploi du temps : De l'exemple (*), il s'ensuit que la fonction de distribution de la distribution uniforme a la forme : F(X) = Son emploi du temps : A partir de l'exemple (**), les caractéristiques numériques de la distribution uniforme sont les suivantes : M(X) = , ré(X) = , (X) = . Exemple. Les bus d'un certain itinéraire circulent strictement selon l'horaire. Intervalle de mouvement 5 minutes. Trouvez la probabilité qu'un passager arrivant à un arrêt attende le prochain bus moins de 3 minutes. Valeur aléatoire X- le temps d'attente du bus par le passager qui s'approche. Ses valeurs possibles appartiennent à l'intervalle (0; 5). Comme X est une quantité uniformément distribuée, alors la densité de probabilité est : F(X) = = = sur l'intervalle (0 ; 5). Pour que le passager attende le prochain bus moins de 3 minutes, il doit se présenter à l'arrêt de bus dans un délai de 2 à 5 minutes avant l'arrivée du prochain bus : Ainsi, R(2 < X < 5) == = = 0,6. La loi de la distribution normale. Ordinaire appelée distribution de probabilité VNS X F(X) = . La distribution normale est définie par deux paramètres : un et σ
. Caractéristiques numériques : M(X) == = = = = + = un, car la première intégrale est égale à zéro (l'intégrale est impaire, la deuxième intégrale est l'intégrale de Poisson, qui est égale à . Ainsi, M(X) = un, c'est à dire. l'espérance mathématique de la distribution normale est égale au paramètre un. Étant donné que M(X) = un, on a ré(X) = = = Ainsi, ré(X) = . Ainsi, (X) = = = , ceux. l'écart type de la distribution normale est égal au paramètre . Général est appelée une distribution normale avec des paramètres arbitraires un et (> 0). normalisé est appelée une distribution normale avec des paramètres un= 0 et = 1. Par exemple, si X– valeur normale avec paramètres un et puis tu= − valeur normale normalisée, et M(tu) = 0, (tu) = 1. Densité de la distribution normalisée : φ
(X) = . Une fonction F(X) distribution normale générale : F(X) = , et la fonction de distribution normalisée : F 0 (X) = . Le diagramme de densité de distribution normale est appelé courbe normale (Courbe de Gauss): Modification d'un paramètre un entraîne un déplacement de la courbe le long de l'axe OH: c'est vrai si un augmente, et vers la gauche si un diminue. Une modification du paramètre entraîne: avec une augmentation, l'ordonnée maximale de la courbe normale diminue et la courbe elle-même devient plate; lorsqu'elle diminue, la courbe normale devient plus "pointue" et s'étire dans le sens positif de l'axe OY: Si un un= 0, a = 1, alors la courbe normale φ
(X) = appelé normalisé. La probabilité de tomber dans un intervalle donné d'une variable aléatoire normale. Soit la variable aléatoire X répartis selon la loi normale. Alors la probabilité que X R(α
< X < β
) = = = Utilisation de la fonction Laplace Φ
(X) = , Enfin on obtient R(α
< X < β
) = Φ
() − Φ
(). Exemple. Valeur aléatoire X répartis selon la loi normale. L'espérance mathématique et l'écart type de cette quantité sont respectivement 30 et 10. Trouvez la probabilité que X Par état, α
=10, β
=50, un=30, =1. R(10< X< 50) = Φ
() − Φ
() = 2Φ
(2). Selon le tableau : Φ
(2) = 0,4772. D'ici R(10< X< 50) = 2∙0,4772 = 0,9544. Il est souvent nécessaire de calculer la probabilité que l'écart d'une variable aléatoire normalement distribuée X en valeur absolue inférieure à la valeur spécifiée δ
> 0, c'est-à-dire il faut trouver la probabilité de réalisation de l'inégalité | X − un| < δ
: R(| X − un| < δ
) = R(a − δ< X< un+ δ
) = Φ
() − Φ
() = = Φ
() − Φ
() = 2Φ
(). En particulier, lorsque un = 0: R(| X | < δ
) = 2Φ
(). Exemple. Valeur aléatoire X distribué normalement. L'espérance mathématique et l'écart type sont respectivement de 20 et 10. Trouvez la probabilité que l'écart en valeur absolue soit inférieur à 3. Par état, δ
= 3, un=20, =10. Puis R(| X − 20| < 3) = 2 Φ
() = 2Φ
(0,3). Selon le tableau : Φ
(0,3) = 0,1179. Ainsi, R(| X − 20| < 3) = 0,2358. Règle des trois sigma. Il est connu que R(| X − un| < δ
) = 2Φ
(). Laisser être δ
= t, alors R(| X − un| < t) = 2Φ
(t). Si un t= 3 et, par conséquent, t= 3, alors R(| X − un| < 3) = 2Φ
(3) = 2∙ 0,49865 = 0,9973, ceux. a reçu un événement presque certain. L'essence de la règle des trois sigma : si une variable aléatoire est normalement distribuée, alors la valeur absolue de son écart par rapport à l'espérance mathématique ne dépasse pas trois fois l'écart type. En pratique, la règle des trois sigma s'applique comme suit : si la distribution de la variable aléatoire étudiée est inconnue, mais que la condition spécifiée dans la règle ci-dessus est remplie, alors il y a lieu de supposer que la variable étudiée est distribuée normalement ; sinon, il n'est pas distribué normalement. Théorème central limite de Lyapunov. Si la variable aléatoire X est la somme d'un très grand nombre de variables aléatoires indépendantes les unes des autres, dont l'influence de chacune sur l'ensemble de la somme est négligeable, alors X a une distribution proche de la normale. Exemple.□ Laissez une quantité physique être mesurée. Toute mesure ne donne qu'une valeur approximative de la grandeur mesurée, car de nombreux facteurs aléatoires indépendants (température, fluctuations de l'instrument, humidité, etc.) influencent le résultat de la mesure. Chacun de ces facteurs génère une « erreur partielle » négligeable. Cependant, le nombre de ces facteurs étant très important, leur effet cumulé génère une « erreur totale » déjà perceptible. En considérant l'erreur totale comme la somme d'un très grand nombre d'erreurs partielles indépendantes les unes des autres, on peut conclure que l'erreur totale a une distribution proche de la normale. L'expérience confirme la validité de cette conclusion. ■ Écrivons les conditions dans lesquelles la somme d'un grand nombre de termes indépendants a une distribution proche de la normale. Laisser être X 1 , X 2 , …, Xp− une séquence de variables aléatoires indépendantes, dont chacune a une espérance et une variance mathématiques finies : M(X k) = un k , ré(X k) = . Introduisons la notation : S n = , Un = , B n = . Désignons la fonction de distribution de la somme normalisée par F p(X) = P(< X). Ils disent à la séquence X 1 , X 2 , …, Xp le théorème central limite est applicable si pour tout X fonction de distribution de la somme normalisée à P→ ∞ tend vers la fonction de distribution normale : La loi de la distribution exponentielle. indicatif(exponentiel) est appelée distribution de probabilité VNS X, qui est décrit par la densité F(X) = où λ
est une valeur positive constante. La distribution exponentielle est déterminée par un paramètre λ
. Graphique de fonction F(X): Trouvons la fonction de distribution : si, X≤ 0, alors F(X) = = == 0; si X≥ 0, alors F(X) == += λ∙
= 1 − e −λx. La fonction de distribution ressemble donc à : F(X) = Le graphique de la fonction recherchée : Caractéristiques numériques : M(X) == λ
= = . Alors, M(X) = . ré(X) =− [M(X)] 2 = λ
− = = . Alors, ré(X) = . (X) = = , c'est-à-dire ( X) = . C'est compris M(X) = (X) = . Exemple. VNS X F(X) = 5e −5Xà X ≥ 0; F(X) = 0 pour X < 0. Trouver M(X), ré(X), (X). Par état, λ
= 5. Par conséquent, M(X) = (X) = = = 0,2; ré(X) = = = 0,04. Probabilité qu'une variable aléatoire à distribution exponentielle tombe dans un intervalle donné. Soit la variable aléatoire X distribué selon une loi exponentielle. Alors la probabilité que X prendra une valeur de l'intervalle ), est égal à R(un < X < b) = F(b) − F(un) = (1 − e −λ b) − (1 − e −λ a) = e −λ a − e −λ b. Exemple. VNS X distribué selon la loi exponentielle F(X) = 2e −2Xà X ≥ 0; F(X) = 0 pour X < 0. Trouver la probabilité qu'à la suite du test X prendra une valeur de l'intervalle ). Par état, λ
= 2. Alors R(0,3 < X < 1) = e- 2∙0,3 − e- 2∙1 = 0,54881− 0,13534 ≈ 0,41. La distribution exponentielle est largement utilisée dans les applications, en particulier en théorie de la fiabilité. Nous appellerons élément un appareil, qu'il soit "simple" ou "complexe". Laissez l'élément commencer à fonctionner au moment opportun t 0 = 0, et après le temps t l'échec se produit. Dénoter par J variable aléatoire continue - la durée de disponibilité de l'élément. Si l'élément fonctionnait parfaitement (avant la panne), le temps est inférieur t, alors, donc, pendant une durée t un refus aura lieu. Alors la fonction de distribution F(t) = R(J < t) détermine la probabilité de défaillance sur la durée t. Par conséquent, la probabilité de fonctionnement sans défaillance pendant la même durée t, c'est à dire. la probabilité de l'événement inverse J > t, est égal à R(t) = R(J > t) = 1− F(t). Fonction de fiabilité R(t) est appelée une fonction qui détermine la probabilité de fonctionnement sans défaillance d'un élément sur une durée t: R(t) = R(J > t). Souvent, la durée de disponibilité d'un élément a une distribution exponentielle dont la fonction de distribution est F(t) = 1 − e −λ t. Par conséquent, la fonction de fiabilité dans le cas d'une distribution exponentielle du temps de disponibilité de l'élément a la forme : R(t) = 1− F(t) = 1− (1 − e −λ t) = e −λ t. La loi exponentielle de la fiabilité est appelée la fonction de fiabilité définie par l'égalité R(t) = e −λ t, où λ
- taux d'échec. Exemple. Le temps de disponibilité de l'élément est distribué selon la loi exponentielle F(t) = 0,02e −0,02 tà t ≥0 (t- temps). Trouvez la probabilité que l'élément fonctionne parfaitement pendant 100 heures. Par convention, taux d'échec constant λ
= 0,02. Puis R(100) = e- 0,02∙100 = e- 2 = 0,13534. La loi exponentielle de fiabilité a une propriété importante : la probabilité de fonctionnement sans panne d'un élément sur un intervalle de temps de durée t ne dépend pas du temps du travail précédent avant le début de l'intervalle considéré, mais dépend uniquement de la durée de temps t(pour un taux d'échec donné λ
). Autrement dit, dans le cas d'une loi exponentielle de fiabilité, le fonctionnement sans panne d'un élément « dans le passé » n'affecte pas la probabilité de son fonctionnement sans panne « dans un futur proche ». Seule la distribution exponentielle possède cette propriété. Donc, si en pratique la variable aléatoire étudiée possède cette propriété, alors elle est distribuée selon la loi exponentielle. Loi des grands nombres L'inégalité de Tchebychev. La probabilité que l'écart d'une variable aléatoire X de son espérance mathématique en valeur absolue inférieure à un nombre positif ε
, pas moins de 1 – : R(|X – M(X)| < ε
) ≥ 1 – . L'inégalité de Chebyshev a une valeur pratique limitée, car elle donne souvent une estimation approximative et parfois triviale (sans intérêt). La signification théorique de l'inégalité de Chebyshev est très grande. L'inégalité de Chebyshev est valable pour DSV et VNS. Exemple. L'appareil se compose de 10 éléments fonctionnant indépendamment. Probabilité de défaillance de chaque élément dans le temps J est égal à 0,05. À l'aide de l'inégalité de Chebyshev, estimez la probabilité que la valeur absolue de la différence entre le nombre d'éléments défectueux et le nombre moyen de défaillances au fil du temps J sera moins de deux. Laisser être X est le nombre d'éléments défaillants au fil du temps J. Le nombre moyen d'échecs est l'espérance mathématique, c'est-à-dire M(X). M(X) = etc = 10∙0,05 = 0,5; ré(X) = npq =10∙0,05∙0,95 = 0,475. On utilise l'inégalité de Chebyshev : R(|X – M(X)| < ε
) ≥ 1 – . Par état, ε
= 2. Alors R(|X – 0,5| < 2) ≥ 1 – = 0,88, R(|X – 0,5| < 2) ≥ 0,88. Théorème de Chebyshev. Si un X 1 , X 2 , …, Xp sont des variables aléatoires indépendantes deux à deux, et leurs variances sont uniformément limitées (ne dépassent pas un nombre constant Avec), alors peu importe la taille du nombre positif ε
, la probabilité d'inégalité |− | < ε
Sera arbitrairement proche de l'unité si le nombre de variables aléatoires est suffisamment grand ou, en d'autres termes, − | < ε
) = 1. Ainsi, le théorème de Chebyshev stipule que si un nombre suffisamment grand de variables aléatoires indépendantes avec des variances limitées sont considérées, alors un événement peut être considéré comme presque fiable si l'écart de la moyenne arithmétique des variables aléatoires par rapport à la moyenne arithmétique de leurs attentes mathématiques sera arbitrairement en valeur absolue petite. Si un M(X 1) = M(X 2) = …= M(Xp) = un, alors, sous les conditions du théorème, l'égalité − un| < ε
) = 1. L'essence du théorème de Chebyshev est la suivante: bien que des variables aléatoires indépendantes individuelles puissent prendre des valeurs éloignées de leurs attentes mathématiques, la moyenne arithmétique d'un nombre suffisamment grand de variables aléatoires prend des valeurs proches d'un certain nombre constant (ou de la Numéro un dans un cas particulier). En d'autres termes, les variables aléatoires individuelles peuvent avoir une dispersion significative, et leur moyenne arithmétique est dispersée petite. Ainsi, on ne peut pas prédire avec certitude quelle valeur prendra chacune des variables aléatoires, mais on peut prédire quelle valeur prendra leur moyenne arithmétique. Pour la pratique, le théorème de Chebyshev est d'une importance inestimable: la mesure d'une certaine quantité physique, qualité, par exemple, céréales, coton et autres produits, etc. Exemple. X 1 , X 2 , …, Xp donnée par la loi de distribution Xp −nα 0 nα R 1 − Le théorème de Chebyshev est-il applicable à une suite donnée ? Pour que le théorème de Chebyshev soit applicable à une suite de variables aléatoires, il suffit que ces variables : 1. soient deux à deux indépendantes ; 2). avait des attentes mathématiques finies; 3). ont des variances uniformément limitées. une). Puisque les variables aléatoires sont indépendantes, elles le sont encore plus deux à deux. 2). M(Xp) = −nα∙+ 0∙(1 − ) +
Théorème de Bernoulli. Si dans chacun de P probabilité de test indépendante R survenance d'un événement MAIS est constante, alors la probabilité que l'écart de la fréquence relative par rapport à la probabilité R sera arbitrairement petit en valeur absolue si le nombre d'essais est suffisamment grand. Autrement dit, si ε
est un nombre positif arbitrairement petit, alors sous les conditions du théorème on a l'égalité − R| < ε
) = 1. Le théorème de Bernoulli stipule que lorsque P→ ∞ la fréquence relative tend à par probabilité pour R En bref, le théorème de Bernoulli peut s'écrire : Commenter. Séquence de variables aléatoires X 1 , X 2 , … converge par probabilitéà une variable aléatoire X, si pour tout nombre positif arbitrairement petit ε
probabilité d'inégalité | X n – X| < ε
à P→ ∞ tend vers l'unité. Le théorème de Bernoulli explique pourquoi la fréquence relative d'un nombre suffisamment grand d'essais a la propriété de la stabilité et justifie la définition statistique de la probabilité. Chaînes de Markov Chaîne de Markov appelé une séquence d'essais, dans chacun desquels un seul des kévénements incompatibles MAIS 1 , MAIS 2 ,…,Un k groupe complet, et la probabilité conditionnelle p ij(S) que dans S-ème essai un événement se produira Un J (j = 1, 2,…, k), à condition que dans ( S– 1)-ème test s'est produit des événements Un je (je = 1, 2,…, k), ne dépend pas des résultats des tests précédents. Exemple.□ Si la séquence d'essais forme une chaîne de Markov et que le groupe complet est constitué de 4 événements incompatibles MAIS 1 , MAIS 2 , MAIS 3 , MAIS 4 , et l'on sait que dans le 6ème procès un événement est apparu MAIS 2 , alors la probabilité conditionnelle que l'événement se produise au 7ème essai MAIS 4 ne dépend pas des événements apparus dans les 1er, 2ème,…, 5ème essais. ■ Les essais indépendants précédemment considérés sont un cas particulier de la chaîne de Markov. En effet, si les essais sont indépendants, alors la survenue d'un événement spécifique dans un essai ne dépend pas des résultats des tests effectués précédemment. Il s'ensuit que le concept de chaîne de Markov est une généralisation du concept d'essais indépendants. Écrivons la définition d'une chaîne de Markov pour des variables aléatoires. Séquence de variables aléatoires X t, t= 0, 1, 2, …, s'appelle Chaîne de Markov avec des états MAIS = { 1, 2, …, N), si , t = 0, 1, 2, …, et pour tout ( P, ., Distribution de probabilité X tà un moment arbitraire t peut être trouvé en utilisant la formule de probabilité totale
Les relations limites suivantes sont valides :
Image 1X
1
4
8
P
0.3
0.1
0.6
Solution : La fonction de distribution peut être écrite analytiquement comme suit :

Figure 2![]() (8)
(8)
2. L'intégrale définie de -∞ à +∞ de la densité de distribution de probabilité d'une variable aléatoire continue est égale à 1 : f(x)dx=1.
3. L'intégrale définie de -∞ à x de la densité de distribution de probabilité d'une variable aléatoire continue est égale à la fonction de distribution de cette variable : f(x)dx=F(x)
Trouver la probabilité qu'à la suite du test, X prenne une valeur appartenant à l'intervalle (0,5 ; 1).
ou alors
D(x)=x 2 f(x)dx- 2 (11*) (30)
(30)
Riz. 4. Graphique de la densité de distribution uniforme (31)
(31)
Riz. 5. Graphique de la densité de la distribution exponentielle (32)
(32)
Riz. 6. Graphique de la densité de la distribution normale (33)
(33) est la fonction gamma d'Euler.
est la fonction gamma d'Euler.11. Densité de la distribution de probabilité d'une variable aléatoire continue et ses propriétés. Caractéristiques numériques de base d'une variable aléatoire continue.
 3)
L'intégrale définie dans la plage de -infini à + infini de la densité de probabilité d'une variable aléatoire continue est égale à un :
3)
L'intégrale définie dans la plage de -infini à + infini de la densité de probabilité d'une variable aléatoire continue est égale à un :
 4)
L'intégrale définie, allant de moins l'infini à x, de la densité de probabilité d'une variable aléatoire continue est égale à la fonction de distribution de cette variable :
4)
L'intégrale définie, allant de moins l'infini à x, de la densité de probabilité d'une variable aléatoire continue est égale à la fonction de distribution de cette variable : 
![]()
12. Loi de distribution normale. Probabilité qu'une variable aléatoire normalement distribuée tombe dans un intervalle donné. Règle des trois sigma.
![]() (augmentation, addition), où M est l'espérance mathématique, σ au carré est la variance, σ est l'écart type de cette valeur. Voici la courbe de Gauss :
(augmentation, addition), où M est l'espérance mathématique, σ au carré est la variance, σ est l'écart type de cette valeur. Voici la courbe de Gauss :
![]() pour la densité de probabilité d'une variable aléatoire normalement distribuée dans l'expression
pour la densité de probabilité d'une variable aléatoire normalement distribuée dans l'expression  , nous obtenons la probabilité qu'à la suite du test, une variable aléatoire normalement distribuée
, nous obtenons la probabilité qu'à la suite du test, une variable aléatoire normalement distribuée